
インプレスさんから、2025年12月3日に発売された「データに触れながら学ぶ統計学」をご恵贈頂きました。また、私は、著者の西田さんと知り合いですし、なんなら、西田さんが先生を務めた「データサイエンス・ブートキャンプ」にも2019年に参加しています。ユーザーとしては、今は、Exploratory Publicを使っています。
この記事には、そんな背景があるんだなーと思って読んでいただければと思います。

(良い意味で)裏切られた!ガチの統計学の本だった
著者の西田さんは、オラクルから独立されて、2016年にExploratory社を立ち上げ、CEOをされています。ご自身もデータサイエンティストとして、例えば、日経ビジネスにも連載実績があります。
同社が開発するExploratoryは、データラングリング(≒データプレップ)、データの可視化、分析、共有を一気通貫に行うソフトウェア製品です。
以下が、同社のトップページにあるイメージです。点線で囲まれたところが、Exploratoryがカバーしている領域を示しています。この記事を読んでいる方は、Tableauに触れたことのある方が多いと思います。Tableauにたとえて言ってみれば、Tableau Prep Builderと、Tableau Desktopが一体化したツールと考えると良いでしょう。
ただし、Tableau Desktopと異なるのは、Exploratoryには機械学習エンジンが搭載されている(=厳密にはR言語の機械学習ライブラリをUIから使える)ので、機械学習のモデル作成や、そのモデルに従った、予測・分類タスクも実行可能です。
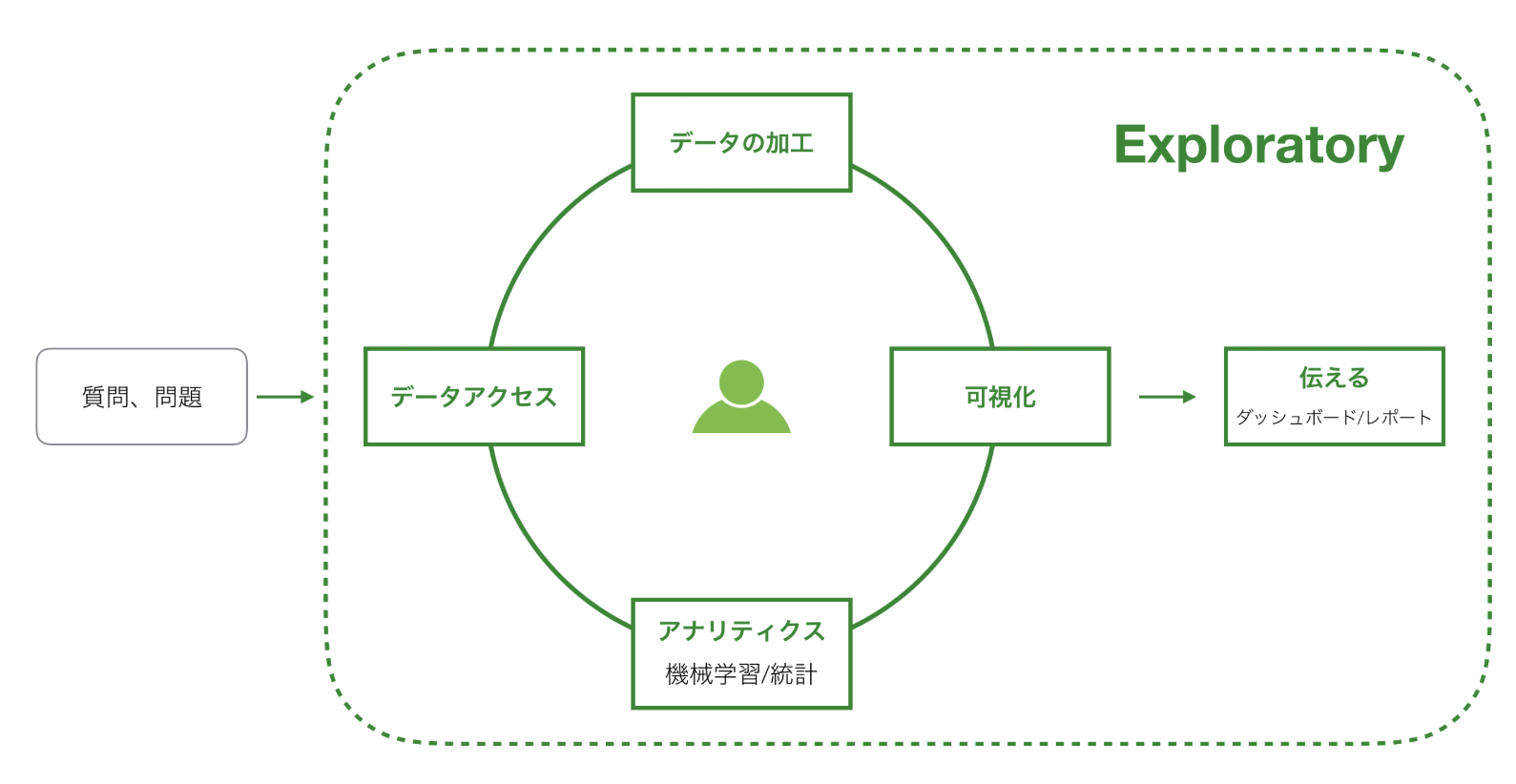
そんな、ExploratoryのCEOの西田さんの著作だったので、Exploratoryというソフトウェアの操作解説の分量が多いのかもな、それはそれで嬉しいけどな。と思って読み始めたのですが、(良い意味で)期待を裏切られました。ガチの統計学の本でした。
どのくらいガチなのかというと、章立てにあらわれているとおり、以下のような章があります。
- 「科学的思考」にひとつの章をあて、「演繹法的なアプローチが限界を迎えたため、観察を繰り返して結論を得る機能法的なアプローチが重要になってきた」という背景を解説し、なぜ統計学が重要なのかを説明している。
- 統計学の専門書でも触れないこともある「確率論」にひとつの章をあて、確率分布(二項分布と正規分布)を解説している。
それに加えて、もちろん、「推測統計と信頼区間」、「仮説検定」、「2つの平均の検定」、「複数の平均の検定」、「割合の検定」など、統計学の中核部をなすトピック、さらには「相関分析」、「多変量分析(線形回帰とロジスティック回帰)」などの分析に関するトピック、そして最後は、統計学をすこしはみ出した「機械学習モデルと予測」までをカバーしています。
こんな人におすすめ
私の専門とするWeb解析では、「パフォーマンスの高い集客方法に予算を傾斜配分する」という施策がよく行われます。すると、パフォーマンスの差についての判断は非常に重要です。例えば、キャンペーンAのコンバージョン率が1.0%、キャンペーンBのコンバージョン率が1.2%だったとき、本当に差があるといえるのか?実際には差がないのに、差があると思い込んでしまうと間違った行動を起こしてしまいます。
そこで、「差」を科学的に、つまり、統計学的な有意性を確認した上で判断することが望ましいです。ところが、Web解析では、一般にあまり統計学的な検証の文化があるとはいえません。(Google アナリティクスにも、統計的検証を行う機能はありません。)それどころか、サイトに訪問していない日本人全体を母集団と考えれば、Web解析に記録されたデータはサンプルだ。という考え方も乏しいように思います。
キャンペーンのパフォーマンスの差については、ときにセッション(=サンプルサイズ)が数百から数万となり、統計的有意性を確認するときのP値は低くなり、比較的小さな差でも「統計的には有意」な差がある。という結論に至ることも多いです。(それが、Web解析業界に統計学的な有意性検証の文化が比較的薄い理由の一つだと思います。)
一方、以下の業務をする人は、サンプルサイズが比較的小さなデータを取り扱うことが多いと思います。
- ヒートマップツールで画面UIのパフォーマンスを判断する
- A/Bテストツールで、画面、あるいはマーケ施策のパフォーマンスを判断する
その場合、統計的な有意性の確認は必須になってくると思われます。そうした仕事をしている人には、この本、おすすめです。また、Exploratoryは有償のツールですが、Exploratory Publicというバージョンはいくつかの制限(一番大きいのは、結果をパブリックに保存しなければいけないところ)がありますが、無料で利用できます。本書のデモを再現するには最適の環境だと思います。
とはいっても統計学の本のなかではとっつきやすい
ガチの統計学の本だった^^; というのが私の感想ではありますが、そうはいっても、著者の西田さんがユーモアに富んだ人でもあり、また、実際に配布されるサンプルデータをExploratoryで可視化しながら学びを深められますので、統計学の本としては、実は、とてもとっつきやすいです。
例えば、統計学的な仮説検定の説明では、フランス出身のフレデリックさんが「自分はフランス出身でワインには詳しい。一口飲むだけで、そのワインがカリフォルニア産か、フランス産か当てられる」と主張する。というシナリオがあり、実際にテストしてみると、10種類のワインのうち、7種類は正解だった。という結果が提示されます。
さて、この場合、フレデリックさんはワインの産地を識別する能力はあると言えるでしょうか?
そんな話から、帰無仮説の話、P値の話、検定の話、、、へと進んでいきます。
こちらにアマゾンへのリンクを置いておきます(アフィリエイトリンクです)ので、何かピンとくるようであれば、お手にとってみてください。