
前回の記事では、Googleのエンジニアの方のXでの投稿をスタート地点として、BigQueryの「ネスト(入れ子)構造」が、クエリの速さとコスト削減に効くということを検証してみました。今回はさらに一歩踏み込み、というか、逆に一歩引いてみて、そもそも、、、である、ARRAY(配列)とSTRUCT(構造体)についての理解を深める目的でこの記事を書いています。
学びのアプローチとして、ARRAY(配列)やSTRUCT(構造体)を含むテーブルを自分たちの手で自作してみます。私たちは、いつもは、GA4がエクスポートした、すでにネストされているテーブルを「与えられ」ますが、自分の手でテーブルを作ってみることによって配列や構造体への理解が進むと思うからです。手を動かすの、大事です。
「1つのセルには、1つの値しか入らない」というExcelのような常識を一度忘れて、データが「立体的」に重なっている感覚をぜひ掴んでみてください。
なぜデータを「入れ子」にする必要があるのか?
これまでのデータベース(私たちが頭の中で真っ先に想像する平坦な表)では、例えば「1人のユーザー」に年齢、性別、住所などの「複数の属性」が紐づく場合、テーブルを2つに分けて保存し、分析のたびに「JOIN(結合)」するのが当たり前でした。
この「当たり前」の世界では、「購買テーブル」(左図)、「ユーザーマスタテーブル」(右図)のように、最初から2つのテーブルがあります。そして、例えば、「この特定商品を買ってくれた人の平均年齢は何歳か?」という問いに対して、2つのテーブルをくっつけて(結合して|JOINして)答えを出す必要があります。
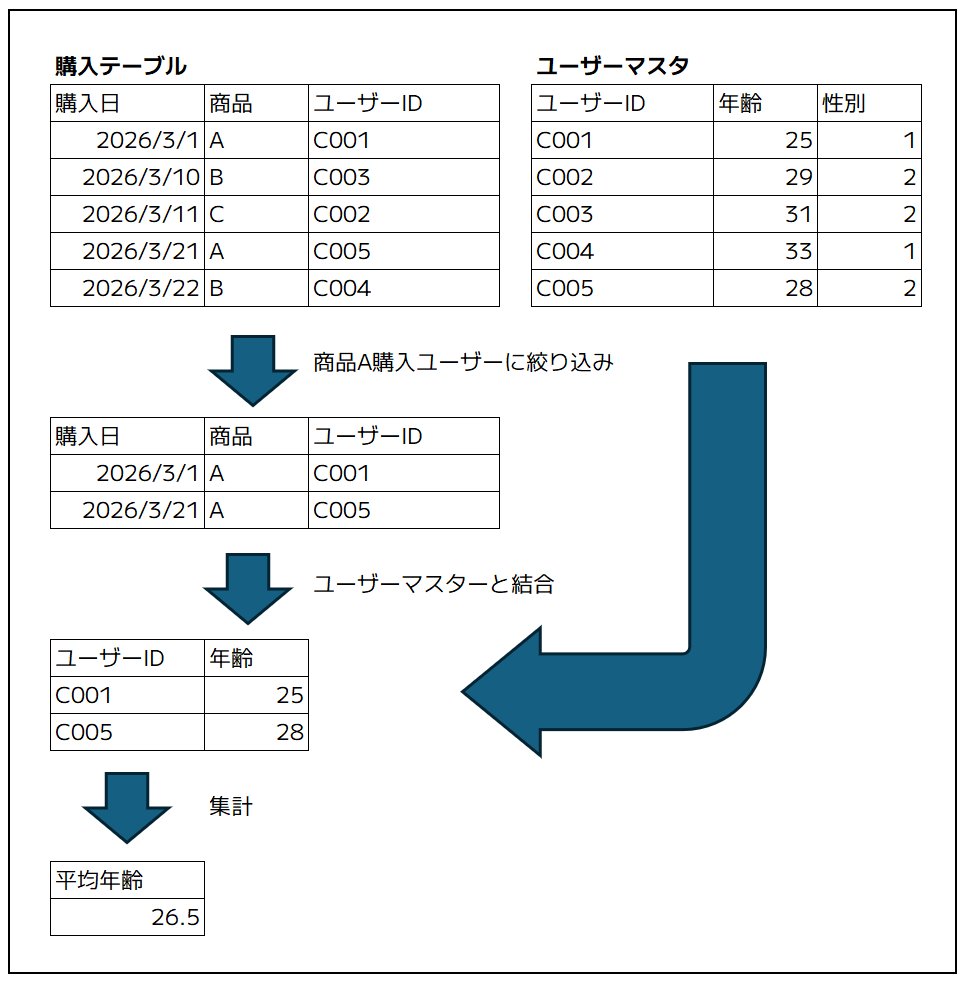
しかし、前回の記事で検証した通り、ビッグデータを扱う現実世界では、この「バラバラのテーブルをくっつける作業(JOIN)」が、処理を遅くし、コストを跳ね上げる最大の原因になります。
そこで「入れ子構造」の出番です。
関連するデータをあらかじめ1つの行の中に「パッキング」して保存しておく。そうすれば、BigQueryはあちこちのテーブルを探し回る必要がなくなり、1箇所を読み込むだけで計算が終わるようになります。これが、「入れ子構造」でデータを持つメリットです。
実践1:ARRAY(配列)を定義してみる
ARRAY(配列型)は、1つの項目に対して「同じ種類のデータ」を複数持たせる形式です。
例えば、「1人の社員」が「複数の部署」を兼務しているようなケースを表現してみましょう。
1人の社員がいくつの部署を兼務するかは事前には分からないので、横に広がるテーブルでは表現しづらいですね。そこで、配列を使って1行で表現してみましょう。
手を動かす:ARRAYの生成
ぜひ、皆さんの手を動かして、BigQueryコンソールで以下のクエリを実行してください。
SELECT
'user_01' AS user_id,
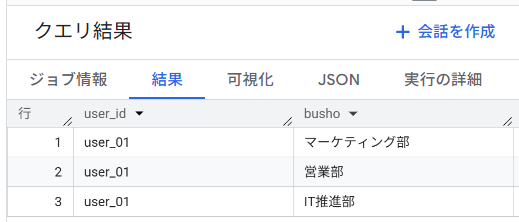
['マーケティング部', '営業部', 'IT推進部'] AS departments;
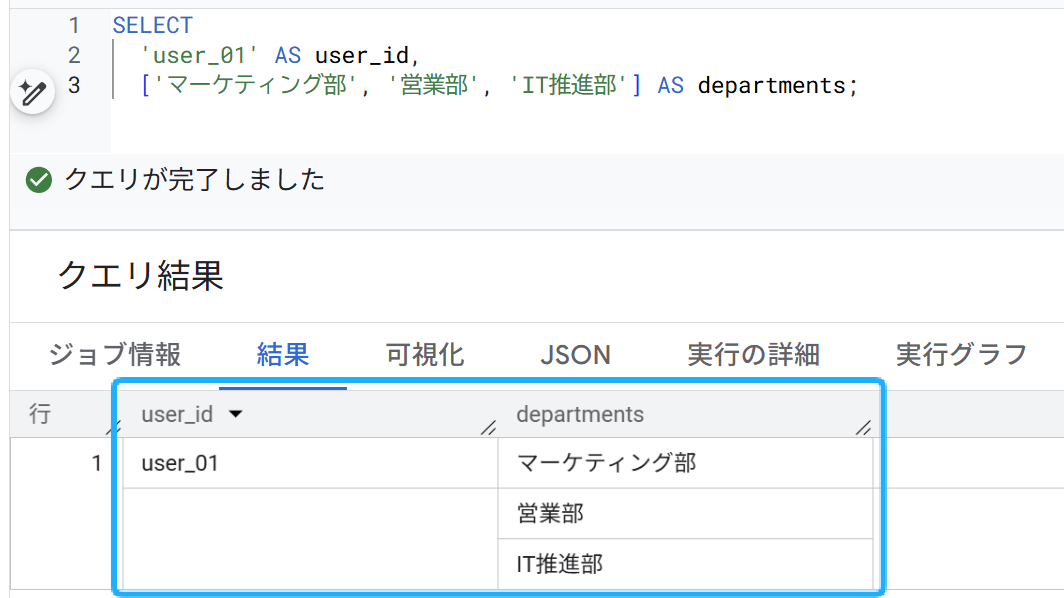
以下の通りの結果を得ることができたはずです。1つの行の、departments カラムの中に、3つの値が縦に並びました。
これがARRAY(配列)です。通常のテーブルなら3行に分けて保存するところを、1行にパッキングできています。
結果テーブルをBigQueryに格納する
では、この結果テーブルを、BigQueryに格納してみましょう。「結果を保存」をクリックすると「BigQueryテーブル」が出てきますので、プロジェクト(データをまとめる1番大きな単位。ユーザーへの権限付与も、課金もプロジェクト単位で行われる)、データセット(データをまとめるフォルダ)を選択し、テーブルに名前を付けて保存します。私の場合、プロジェクトは、bq-verification、フォルダ名は、array_struct、テーブル名は busho としました。
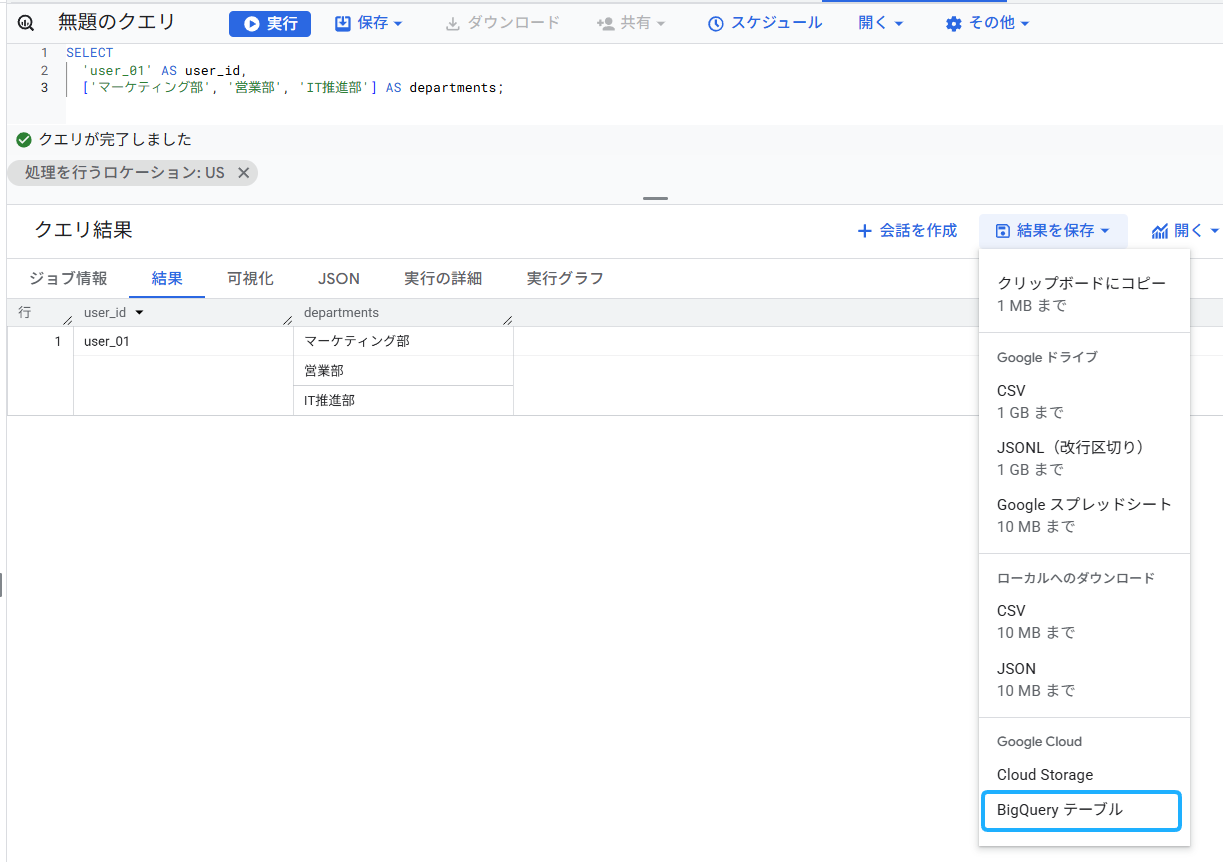
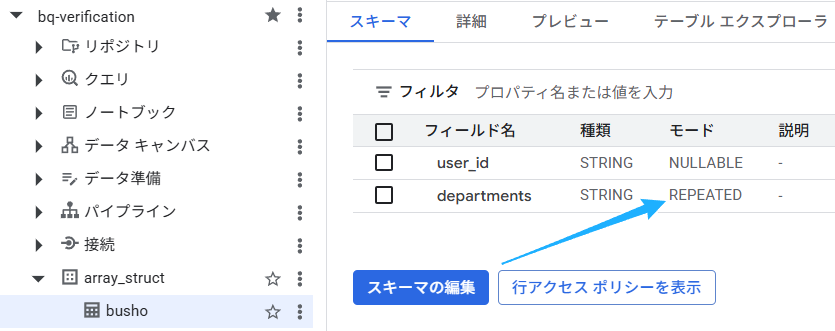
ちなみに、作成した bushoテーブルで、departments列は、種類がSTRING(文字列型)、モードがREPEATEDとなっています。REPEATEDを見たら、「あ、配列が使われているな」と思ってください。
分析:UNNESTで「平たくする」操作
ARRAYの中に閉じ込められたデータは、そのままでは集計に使えません。そこで、集計をする場合には、配列を一時的に「縦方向の行」に展開する UNNEST という演算子を使います。以下のSQL文をコンソールの「クエリエディタ」に貼り付けて、プロジェクト、データセット、テーブルの各名前をご自身の環境に合わせて変更した上で、実行してみてください。
SELECT user_id,busho
FROM `bq-verification.array_struct.busho`, UNNEST(departments) AS busho
以下の通り、これまで一つのセルの中で縦方向に格納されていた departments の値が、busho列に展開されました。UNNESTという関数で行に展開された1列3行の各行を、FROM句で元のテーブルとカンマでつなぐというのがポイントです。(専門的には「クロスジョイン」と呼びますが、少なくともこの記事においては覚えなくて大丈夫です。)
UNNESTを使えば、いつでも、見慣れた平たい表(フラットテーブル)にできるということがわかると、ARRAY(配列)が怖くなくなりますね。
実践2:STRUCT(構造体)を定義してみる
次に、STRUCT(構造体)です。これは、種類が違うデータを1つの「グループ」にまとめる機能です。
例えば、「名前」(文字列型)、「年齢」(整数型)、「居住地」(文字列型)という3つの項目を、バラバラのカラムではなく「ユーザー情報」という1つの塊として扱ってみましょう。
手を動かす:STRUCTの生成
コンソールで、以下のクエリを実行してみてください。STRUCTの中身を見ると、構造上、name=田中太郎、age=28、city=東京都を表していることが分かります。このような「名前=値」という記述方法を「キーバリューペア」と呼びます。
SELECT
101 AS id,
STRUCT(
'田中太郎' AS name,
28 AS age,
'東京都' AS city
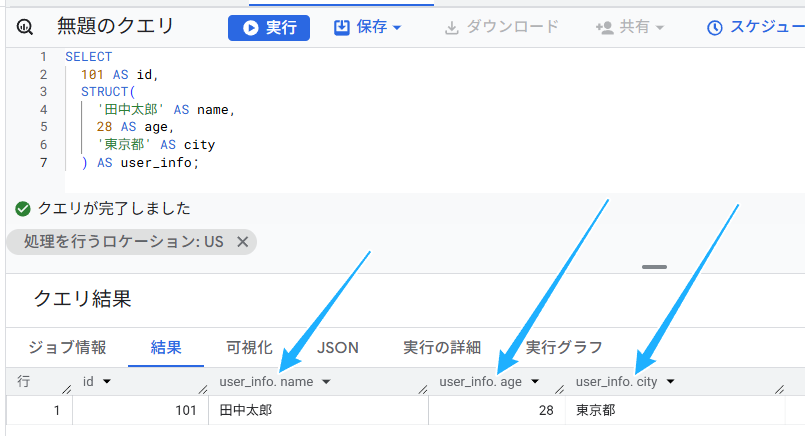
) AS user_info;
以下が実行結果です。ARRAYと違い、一つの列に格納されるのではなく、name、age、cityのそれぞれが、一つの列を構成しています。ただし、それらの前には、共通して「user_info.」がついていて、同じグループなのだということが分かります。
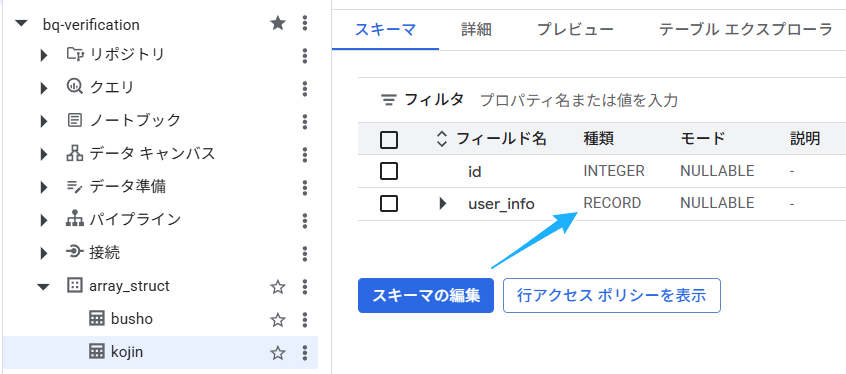
こちらのテーブルもBigQueryに保存しましょう。私の場合、プロジェクトとデータセットは同じで、テーブルの名前だけ、kojin としました。ちなみに、この kojinテーブルのスキーマ(列の説明)を見てみると、「種類」が「RECORD」になっています。ここをみると、「あ、構造体を使って複数列をグループ化しているんだな」と気づくことができます。
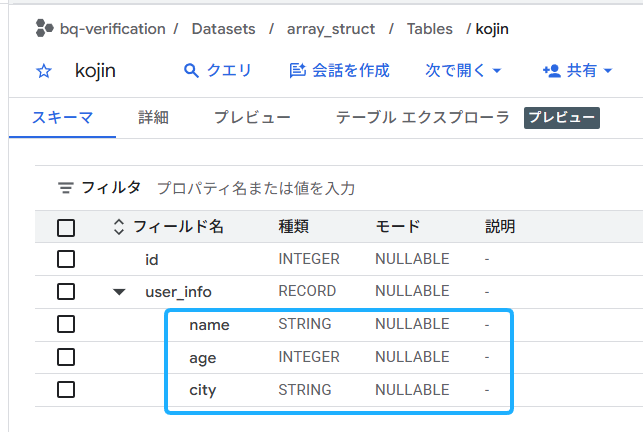
ちなみに、user_infoの左側にある横向きの▲をクリックすると、以下の通り、グループ化された列と、そのデータ型(種類)が確認できます。user_infoの下に、name、age、cityがぶら下がる「階層構造」になっていることも理解できます。
分析:ドット記法によるアクセス
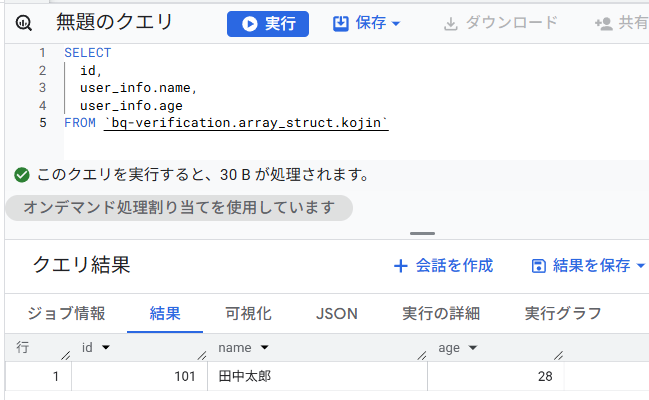
分析のためにSTRUCTの中身を取り出すには、フォルダの階層を辿るようにドット(.)を使います。以下のSQL文をコンソールから実行してみてください。user_info STRUCTからは、配下にある、nameとageを取得しています。
SELECT
id,
user_info.name,
user_info.age
FROM `bq-verification.array_struct.kojin`
結果は以下の通り、STRUCTの中の、nameとageを取得することができました。STRUCTから、その配下の列を取得するのは難しくありませんね。
実践3:JSONアップロードで「GA4の正体」を再現する
ARRAY(配列)、STRUCT(構造体)を含むテーブルを作成できるようになったところで、いよいよ、ARRAYとSTRUCTを組み合わせた「ARRAY of STRUCTS(構造体の配列)」に挑戦します。これこそが、GA4の event_params で採用されている構造です。
手を動かす:JSONの作成とロード
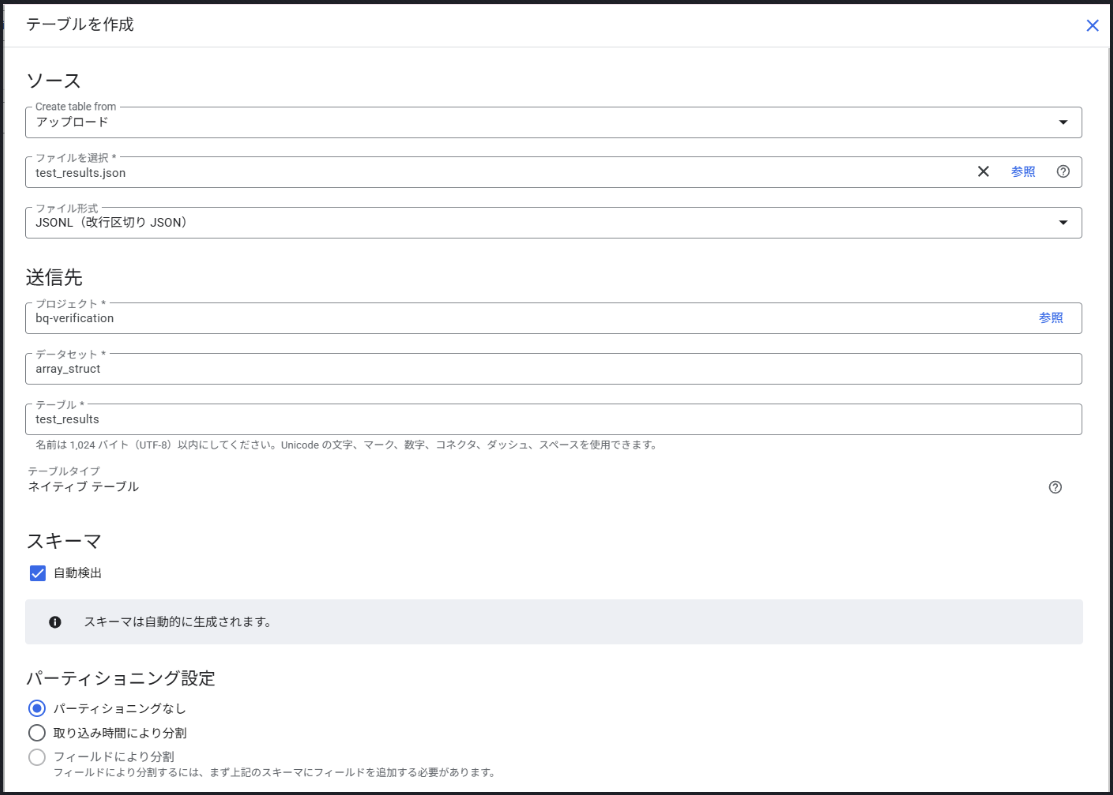
以下の4行をテキストエディタに貼り付け、文字コードをUTF-8、ファイル名 test_results.json として保存し、BigQueryにアップロードして、新しいテーブルを作成してください。
{"s_id": "S001", "gender": "male", "tests": [{"subject": "Japanese", "score": 80}, {"subject": "Social", "score": 75}, {"subject": "English", "score": 90}]}
{"s_id": "S002", "gender": "female", "tests": [{"subject": "Japanese", "score": 95}, {"subject": "Social", "score": 85}, {"subject": "English", "score": 100}]}
{"s_id": "S003", "gender": "male", "tests": [{"subject": "Japanese", "score": 60}, {"subject": "Social", "score": 70}, {"subject": "English", "score": 65}]}
{"s_id": "S004", "gender": "female", "tests": [{"subject": "Japanese", "score": 85}, {"subject": "Social", "score": 80}, {"subject": "English", "score": 75}]}
私が、該当のJSONファイルをアップロードしてテーブルを作成している画面は以下の通りです。ファイル形式を「JSONL」、スキーマを「自動検知」にするのがコツです。この画面は、コンソールの左カラムにある、配下にテーブルを格納したいデータセット名の三点リーダーをクリックし「テーブルを作成」に進むと出てきます。
以下が作成したテーブルのスキーマですが、「種類」が「RECORD」、「モード」が「REPEATED」になっているのが確認できます。STRUCT(構造体)、が、ARRAY(配列)に組み込まれていることが分かります。
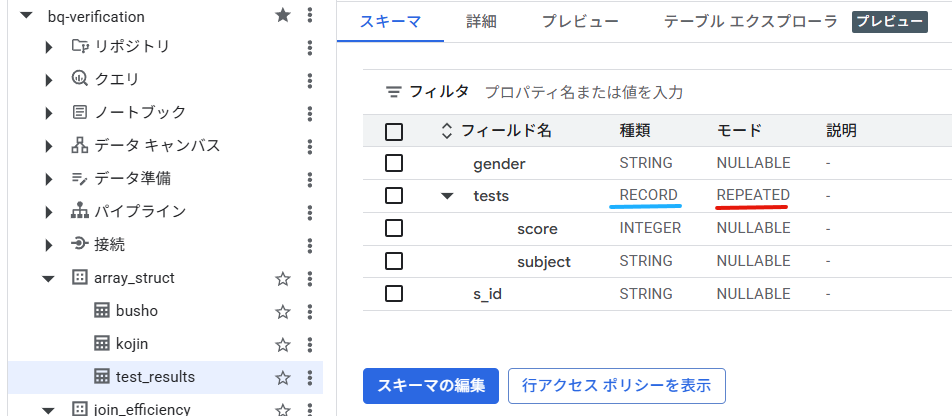
これがGA4のテーブルの正体
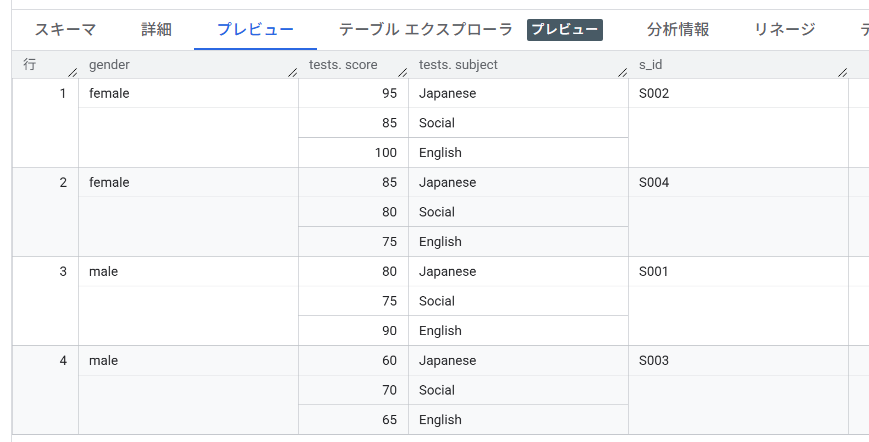
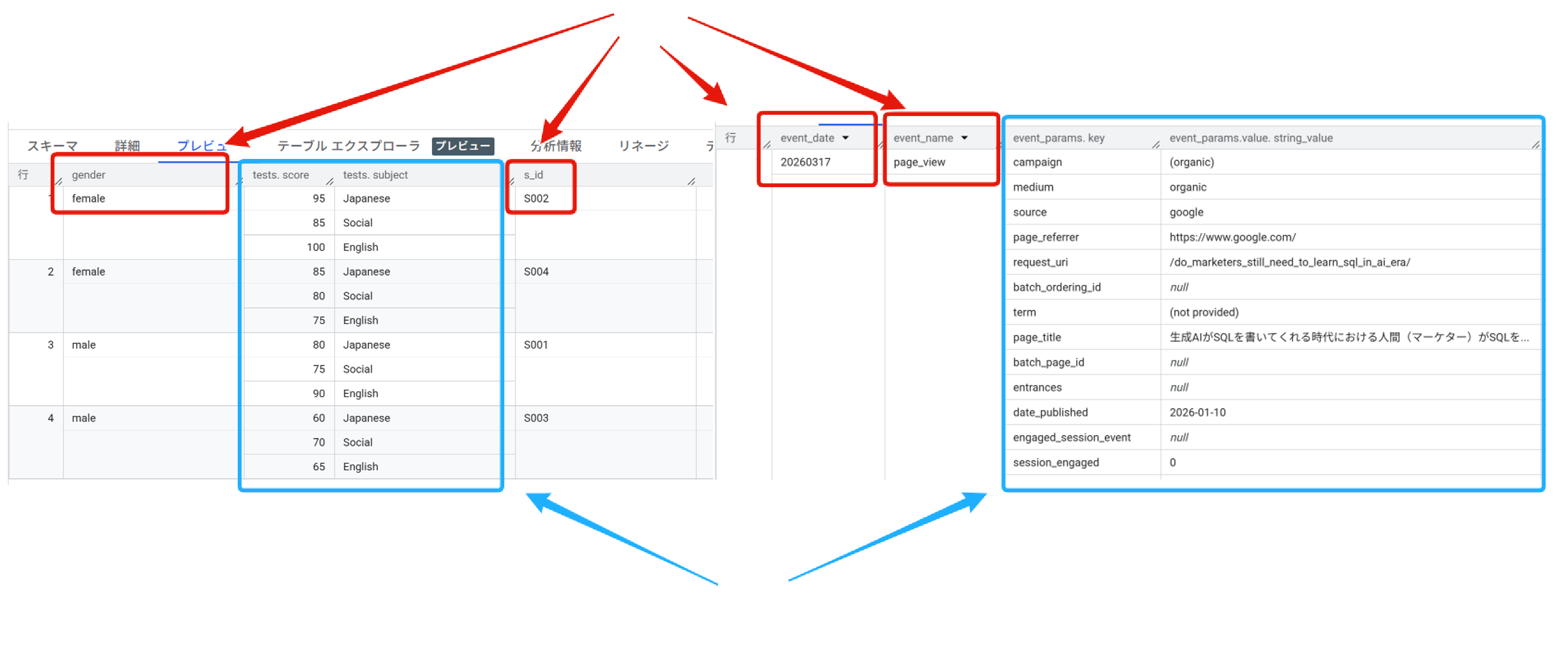
完成したテーブルのプレビューを見てください。(列の順番はテーブルの構造とは無関係なので、気にしないでください。結果テーブルを取得するときには、SELECT句の中で任意の順番で列を取り出せます。)
「s_idで識別される1人の生徒(1行)」の中に、「キーと値のセット(STRUCT)」が「複数(ARRAY)」入っていますね。この構造は、GA4がBigQueryにエクスポートしたテーブルの、event_params列そっくりです。
以下で、GA4がBigQueryに出力するテーブルと構造を比較してみました。以下がそれぞれ構造的に相当する部分です。
- s_id(生徒ID)やgender(性別) : GA4の event_id や event_name (赤色)
- tests(テスト結果の配列) : GA4の event_params (水色)
分析:UNNESTを使って「平均値」を自由自在に操る
「テストの点数テーブル」と「生徒マスター」のように2つのテーブルを使うのではなく、ARRAYとSTRUCTを含んだこの構造の面白いところは、一度 UNNEST でバラしてしまえば、あとは通常のSQLと同じ感覚で集計できる点です。例を3つ挙げてみます。
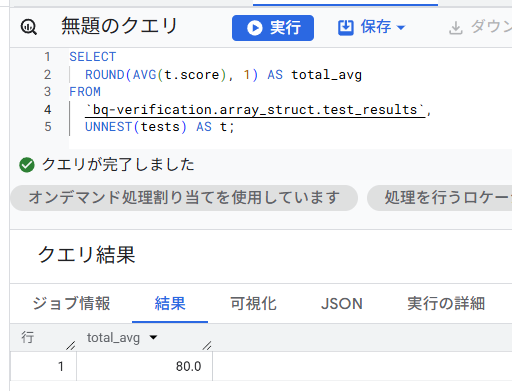
A. 全体の平均スコア(全生徒・全科目)
すべてのネストを解いて、全テスト結果の平均を出します。
SELECT
ROUND(AVG(t.score), 1) AS total_avg
FROM
`bq-verification.array_struct.test_results`, UNNEST(tests) AS t;
結果はこちら。
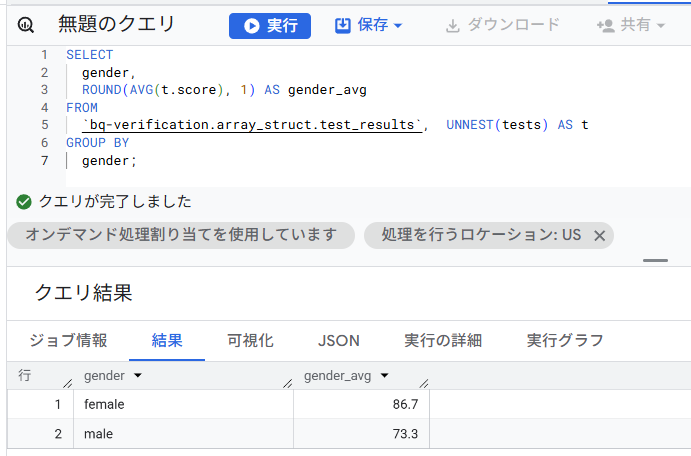
B. 男女別の平均スコア
性別(gender)はSTRUCTの外側にある項目なので、そのまま GROUP BY の軸として利用できます。
SELECT
gender,
ROUND(AVG(t.score), 1) AS gender_avg
FROM
`bq-verification.array_struct.test_results`, UNNEST(tests) AS t
GROUP BY
gender;
結果はこんな感じ。
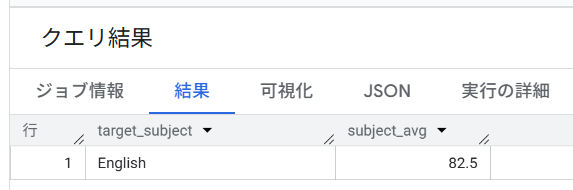
C. 「英語(English)」だけの平均スコア
UNNEST で展開した後に、WHERE 句を使って特定の科目(subject)だけに絞り込んで集計します。
SELECT
t.subject,
ROUND(AVG(t.score), 1) AS subject_avg
FROM
`bq-verification.array_struct.test_results`, UNNEST(tests) AS t
WHERE
t.subject = 'English'
GROUP BY
t.subject;
上記の、FROM 句に書くUNNESTは、tests(構造体の配列)の中身をすべて展開して『データを縦に増やす(全展開する)』ための定石でした。 一方で、GA4などの実務でよく使うのが、これから紹介する SELECT 句の中でUNNESTを使うテクニックです。これはデータを増やすのではなく、配列を仮想的に展開した中から『特定のデータだけをピンポイントで抜き出して利用する』ための定石になります。
以下のSQL文では、testsを展開し、「subjectがEnglishに一致する行」からだけ、scoreを取得して平均する。という処理をしています。
GA4テーブルの場合には、こちらの方法が多用されます。
SELECT
'English' AS target_subject,
ROUND(AVG(
(SELECT score FROM UNNEST(tests) WHERE subject = 'English')
), 1) AS subject_avg
FROM
`bq-verification.array_struct.test_results`;
結果はいずれも、以下の通りとなります。
まとめ:「作る」ことで見えてくるデータの構造
さて、まとめです。今回、最小限のデータセットを自分の手で作ってみたことで、以下のことが実感できたはずです。
- ARRAY(配列) は、同じデータ型の値を「縦のリスト」として1行に収める。
- STRUCT(構造体) は、関連する項目を「横のパッケージ」として1つのカラムにまと階層化する。中身はキーバリューペア(「名前=値」の形)になっている。
- ARRAY of STRUCTS(構造体の配列) は、その両方を組み合わせて、複雑な事象を1行に凝縮する。ARRAYをUNNESTしてほどけば、
1) FROM句で元のテーブルとカンマでつなぎARRAYの全部の行が反映されたフラットテーブルにすることができる。
2) SELECT xxx FROM UNNEST(yyyy) WHRE s=t の構文で狙った値だけを取得できる。
GA4のテーブルを見て「難解だ」と感じていたのは、その構造を外側から眺めていたからです。一度自分で定義し、UNNEST で展開する感覚を掴んでしまえば、BigQueryでの分析スキルは飛躍的に向上します。
この「データの深度」を自由に扱えるようになると、SQLでできることの幅がぐっと広がります。ぜひ、ご自身の実際のデータでも試してみてください。