前回のブログで、BigQueryのGSCデータを利用して「新しく登場したクエリ」のリストを取得する という記事を書いたのですが、(このサイトにアップしているブログ記事の中では)比較的好評な気がしたので、真正面から二匹目のドジョウを狙ったのがこの記事ですwww
順位が大きく変動したクエリのダッシュボード
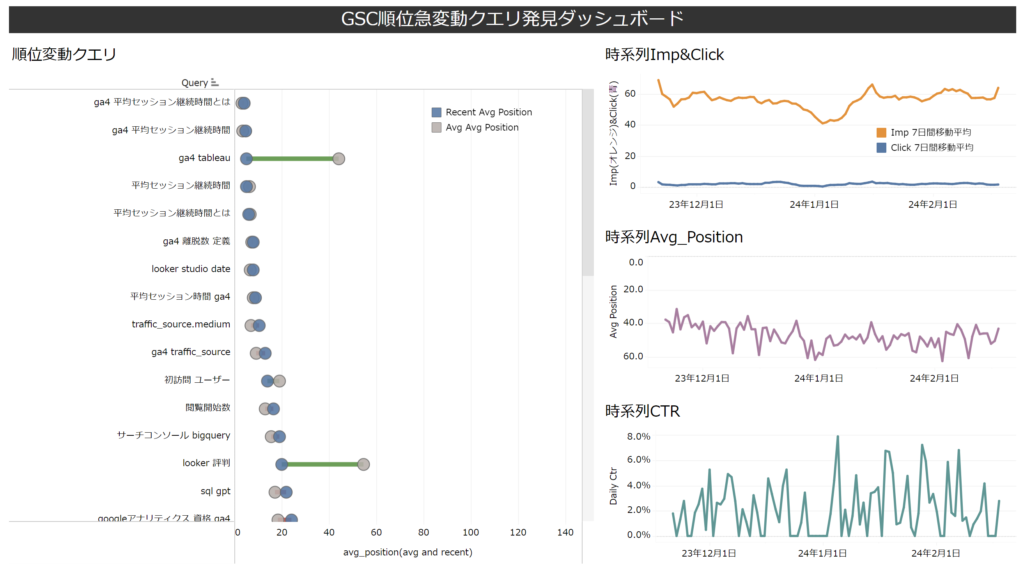
本ブログ記事後半で紹介するSQL文をデータソース(カスタムクエリ)として作成したTableauのダッシュボードを紹介します。画像クリックで拡大されます。
以下はスクリーンショットですが、左側の「順位変動クエリ」でクエリをクリックすると、そのクエリの時系列の変動が、右側の3段の折れ線グラフで確認できるようになっています。動くものを触ってみたいという方は、Tableau Publicにパブリッシュしてある 順位が大きく変動したクエリのダッシュボード をご確認ください。
ダッシュボードの使い方
ダッシュボードの使い方を軽く説明しますね。
左側の「順位変動クエリ」グラフについて
左側に配置している順位変動クエリのシートは、クエリ別の平均掲載順位を●の位置で表しています。●が2つあるうち、青が、最新の日付(今日から3日前)の平均掲載順位を示しています。灰色のは、「3か月前から3日前までの平均の平均掲載順位」です。2つの●をつなぐ線に色がついていて、良い方の変化なら緑、悪い方の変化なら赤になっています。
「平均の平均掲載順位」については、「平均」が2つ繋がっているため、GSCに不慣れな人にはどのような指標か理解しづらい面があると思います。が、もともとの指標が「平均掲載順位」なので、「平均掲載順位」を平均したもの。と理解していただくのが良いです。
具体的には、例えば、ある日、あるクエリが1位で3回インプレッションして、2位で5回インプレッションしたら、以下の計算式で平均して計算されます。
{(1x3) + (2x5)}/8 = 1.625
その「平均順位」を日単位で取得した値は、例えば87日間、すべての日でインプレッションしていれば、87個のあるはずですね。それら87個の「平均掲載順位」をすべて足し合わせ87で割ると、「平均の平均掲載順位」が求まります。
SQL文
上記のダッシュボードを実現したデータソースのSQL文を以下に紹介します。気をつけていただきたいのは、1つのダッシュボードを作成するために2つのデータソースに接続していることです。
具体的には、ダッシュボードの左側にある「順位変動クエリ」は、仮想テーブルoutput1から取得した全レコード全カラムから作成しています。右側の、折れ線グラフについては、仮想テーブルoutput2から全レコード、全カラムを取得しています。(以下のSQL文サンプルは、最終行を見て頂くと分かる通り、output1テーブルから結果を取得しています。)
WITH past3m AS (
SELECT
query,
data_date,
SUM(impressions) AS impressions,
SUM(clicks) AS clicks,
SUM(clicks) / SUM(impressions) AS daily_ctr,
(SUM(sum_position) / SUM(impressions)) + 1.0 AS avg_position
FROM `kazkida-com-stats.searchconsole.searchdata_url_impression`
WHERE
DATE(data_date) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 3 MONTH) AND DATE_SUB(CURRENT_DATE(), INTERVAL 3 DAY)
GROUP BY
query,
data_date
), p3m_query_summary AS (
SELECT
query,
SUM(impressions) / COUNT(DISTINCT data_date) AS avg_daily_imp,
SUM(clicks) / COUNT(DISTINCT data_date) AS avg_daily_click,
AVG(daily_ctr) AS avg_daily_ctr,
AVG(avg_position) AS avg_avg_position,
STDDEV(avg_position) AS stddev_avg_position
FROM
past3m
GROUP BY
query
HAVING COUNT(DISTINCT data_date)>45
AND stddev_avg_position / avg_avg_position > 0.25
), recent AS (
SELECT
query,
(SUM(sum_position) / SUM(impressions)) + 1.0 AS recent_avg_position
FROM
`kazkida-com-stats.searchconsole.searchdata_url_impression`
WHERE
DATE(data_date) = DATE_SUB(CURRENT_DATE(), INTERVAL 3 DAY)
GROUP BY
query
), output1 AS (
SELECT
*,
IF(recent_avg_position > avg_avg_position + stddev_avg_position, "bad_change", "good_change") AS change_direction
FROM (
SELECT
p3m.query,
p3m.avg_daily_imp,
p3m.avg_daily_click,
p3m.avg_daily_ctr,
p3m.avg_avg_position,
p3m.stddev_avg_position,
recent.recent_avg_position
FROM
p3m_query_summary AS p3m
JOIN
recent ON p3m.query = recent.query
)
WHERE
recent_avg_position > avg_avg_position + stddev_avg_position
OR
recent_avg_position < avg_avg_position - stddev_avg_position
ORDER BY
avg_daily_imp DESC
), output2 AS (
SELECT
*
FROM
past3m
WHERE
query IN (SELECT query FROM output1)
)
SELECT * FROM output1
SQL文の解説
簡単にSQL文を解説すると、以下となります。
最初の仮想テーブル:past3m
日付(data_date)別、クエリ(query)別に、インプレッションの合計、クリックの合計、CTR、平均掲載順位を集計しています。期間については、今日を基準に、(最新のデータがBigQueryのテーブルに確認される)3日前から、3か月前を対象にしています。(なので、実行すると、結構毎日、顔ぶれが変わるはずです。なので、実際に利用する場合には、チラっとで良いので毎日確認するのが望ましいです。)
2番目の仮想テーブル:p3m_query_summary
最初の仮想テーブルpast3mを対象に、クエリ(query)別に、日別のインプレッションの平均、日別のクリックの平均、日別のCTRの平均、日別の平均掲載順位の平均、日別の平均平均掲載順位の標準偏差を集計しています。さらに、HAVING句で、以下の2つの絞り込みを行っています。
- データがあまり記録されていないクエリを除外するために、45日以上データが記録されていたクエリに絞り込んでいます。
- そもそも順位変動が大きい(=標準偏差が大きい)クエリを除外するために、変動係数(標準偏差/平均)が0.25より小さいクエリに絞り込んでいます。)
上記の絞り込みについては、対象となるクエリの種類数を確認しながら、多すぎるようであれば絞り込みを強め、少なすぎるようであれば絞り込みを緩めると良いでしょう。
3番目の仮想テーブル:recent
最新のデータが記録されている、今日から3日前の、クエリごとの平均掲載順位を求めています。
4番目の仮想テーブル:output1
2つの仮想テーブル、p3m_query_summaryと、recentを、queryを結合キーとして内部結合しています。クエリごとに取得している指標は、以下です。
- 日別の平均インプレッション(avg_daily_imp)
- 日別の平均クリック(avg_daily_click)
- 日別の平均CTR(avg_daily_ctr)
- 過去3ヶ月前から3日前までの日別の平均掲載順位の平均(avg_avg_position)
- 過去3ヶ月前から3日前までの日別の平均掲載順位の標準偏差(stddev_avg_position)
さらに、変化の方向を、bad_change (avg_avg_position < recent_avg_positionの場合)、あるいは、good_change (avg_avg_position > recent_avg_positionの場合)でフラグ付しています。
出力は、クエリ別の平均の平均掲載順位(p3m_query_summaryに格納されている、avg_avg_position)と、直近の平均掲載順位(recentに格納されているrecent_avg_position)を比較し、平均の平均掲載順位から、標準偏差(p3m_query_summaryに格納されている stddev_avg_position)の1倍より離れているクエリに絞り込んでいます。
5番目の仮想テーブル:output2
ダッシュボードで、時系列グラフを描くための仮想テーブルです。すべてのクエリを取得する必要はないので、output1テーブルで絞り込まれた上で残ったクエリだけを対象としています。
まとめ
如何でしたでしょうか?
この記事で紹介した可視化方法がベストかどうかはわかりませんが、BigQueryにエクスポートされたGSCのデータを利用すると、このような可視化ができる、という一例にはなっているのではないかと思います。
この記事に関連した学習リソース
この記事をここまで読んでいただいた方は、もれなく、BigQuery(SQL)って、やっぱりできた方がいいな!!と思っていただいたんじゃないかと思います。
そういえば、SQLについて、学習用の良い動画講座があるんですよ。たくさんのレビューを頂き、5点満点中4.6点と、お陰様で評判も良いようです。よろしければどうぞ。(画像をクリックするとUdemy.comにジャンプします。)

え?SQLは本で勉強したい?なるほど、では、こちらをどうぞ。(アマゾンのアフィリエイトリンクです。画像をクリックするとアマゾンにジャンプします)