
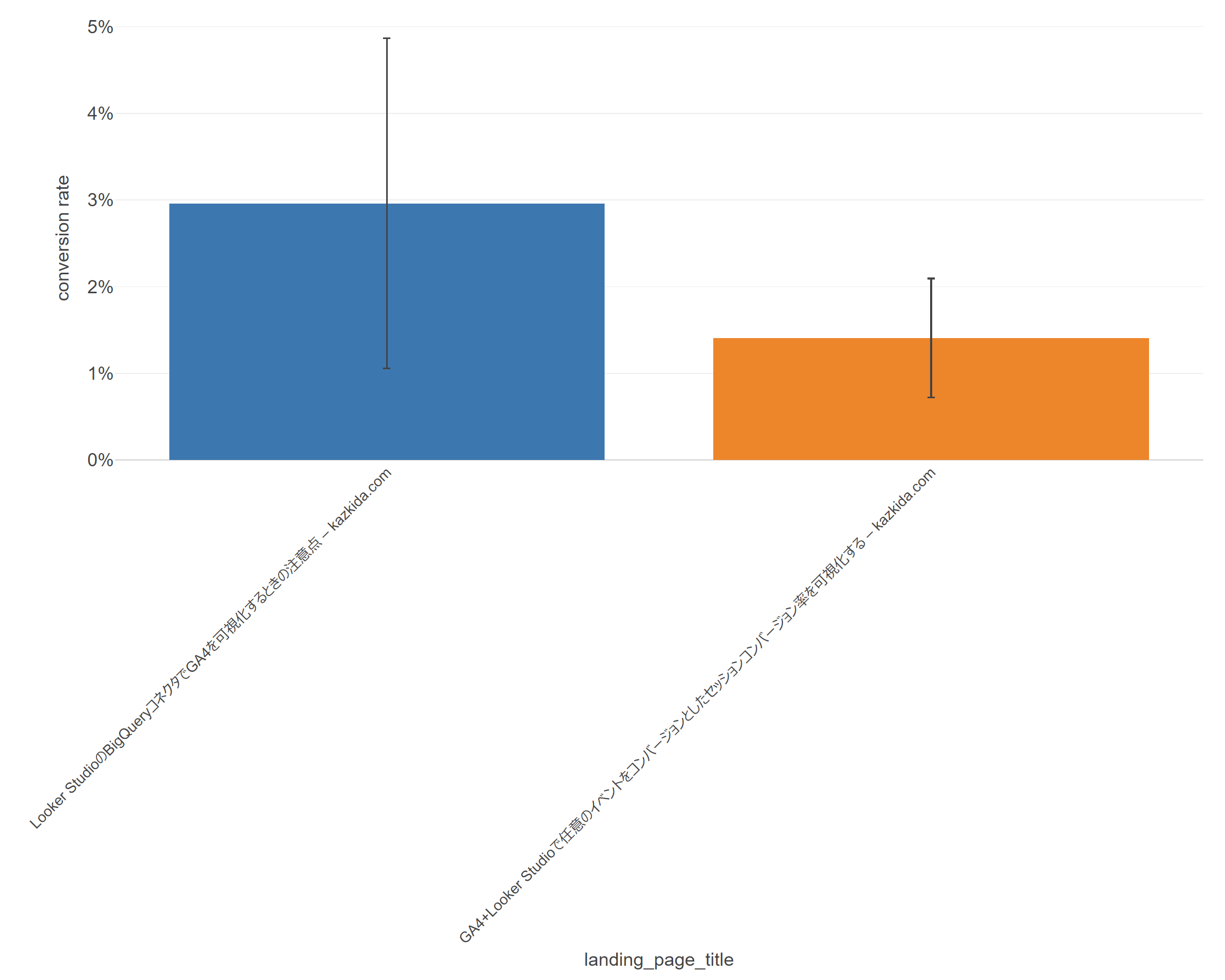
以下のグラフを見てください。2つのランディングページ別のコンバージョン率を示した、見慣れたバーチャートの上に「ちょんまげ」がついています。もちろん、正式名称は「ちょんまげ」ではなく「エラーバー」と言います。このブロク記事では、ちょんまげ、もとい、エラーバーについて「数式を使わずに!」解説していますので、初めて聞いたよ、という方は、ぜひ、本記事を読んでいってください。
エラーバー自体には馴染みのある方でも、「エラーバーってエクセルで出そうとすると結構ゴニョゴニョしなくちゃいけないよね、面倒なんだよな。」という方は大勢いらっしゃるかと思います。この記事のエラーバー付きバーチャートはすべてExploratory Publicという無料ソフトで描いています。描き方の記事はこちらで別記事(Exploratoryでエラーバー付きバーチャートを作る方法)にしています。
エラーバーが活躍する状況
エラーバーは、取得したデータが「サンプル」の場合に活躍します。全数調査が諸般の事情でできないときに行う「サンプル調査」のときですね。Webマーケティングで言うと、A/Bテストがサンプル調査として真っ先に想起されます。一方、「ランディングページ別のコンバージョン率」だって、考えようによっては立派なサンプル調査です。
つまり、「全数」を「日本全体のユーザー」であったり、「顧客になってくれる可能性のある全ユーザー」と想定すれば、Google アナリティクスで取得できているデータはそのうちの一部、つまり、サンプルということになります。
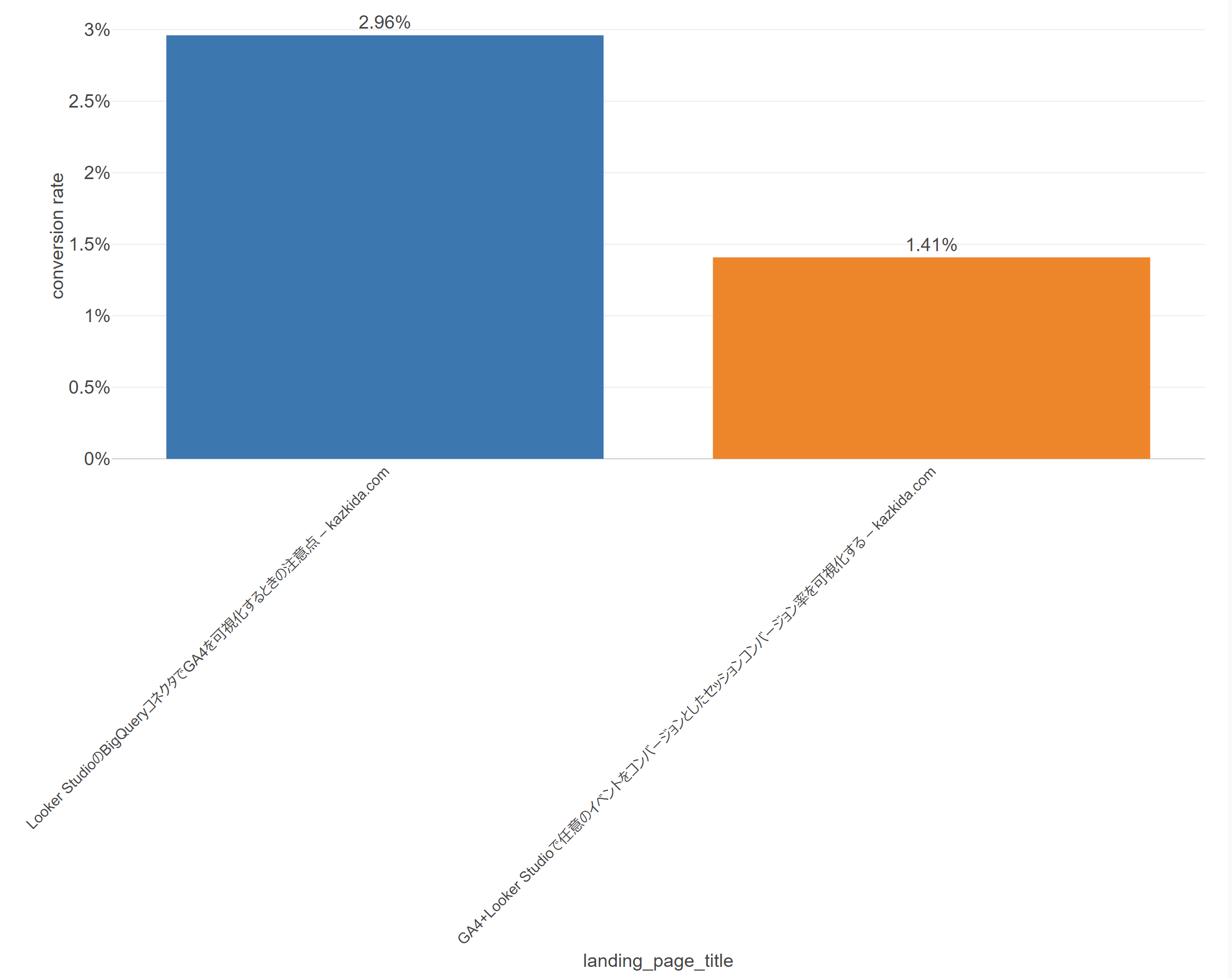
Google アナリティクスで取得できたデータをサンプルとして捉えたとき、例えば、以下の2つのランディングページ別のコンバージョンレートの差、つまり、2.96%と、1.41%の差は統計的に有意なのか?を確認する必要がでてきます。そのとき活躍するのがエラーバー。という訳です。
エラーバーが示すのは区間推定の幅(=信頼区間)
その形を見ていただくとわかりますが、エラーバーは、Y軸方向に、「幅」を示しています。この幅のことを「信頼区間」と呼びます。信頼区間には必ず「●%信頼区間」という形で「●%」が着きます。この「●%」が何の確率かについては誤解も多いようですが、以下の通りに理解してください。(95%信頼区間で説明します。)
- (現実には行うことができないが)全数調査を行ったときに初めて明らかになる「母集団(=全数)の本当の値(母数<ぼすう>」というものがあるのだ。と考える。(想定する母集団の本当の値のことを、それが平均値であれば、「母平均<ぼへいきん>」、比率であれば「母比率<ぼひりつ>」と呼びます。)
- 母数が分かれば(それは全数調査の結果であり、ゆらぎのないものであるから)それが真の値(真値<しんち>)である。真値に差があれば、それは本当に差があったということになる。しかし、母数(=真値)は全数調査をしない限り分からないので、サンプルから「推定」する。
- サンプル調査ということは、(少なくとも論理上は)同じ調査を何回も行うことができる(と考える。袋の中に、赤の玉が7個、白の玉が3個入っています。その中の1個の玉をサンプルとして取得し、記録します。みたいなのがサンプル調査。なので、取得した玉の色を確認後、再び袋に戻せば何回も調査できる。そういう意味合いでサンプル調査は何度もできる。)
- 95%信頼区間というのは、同じサンプル調査を、仮に100回行えば、そのうちの95回はその区間に真値が入っている。という区間のことです。(確率の表現では、分母と分子がそれぞれ何か?を明らかにするのが大事だと考えています。この場合は、「サンプル調査の結果が真値を含む回数」が分子、「サンプル調査の全回数」が分母です。)
- で、95%(100回中95回)というのは結構高い確率なので、区間推定の区間の中におおよそ真値がある。と考えてもよいだろうということになっています。
信頼区間の「幅」の特徴
数式は(冒頭でのお約束どおりに)出しませんが、エラーバーが示す信頼区間の「幅」には以下の特徴があります。
- ●%信頼区間の●の値を小さくすれば、(例えば、95%信頼区間を、90%信頼区間に変更すれば)幅は小さくなります。
- サンプルサイズ(サンプル調査に用いるデータの個数。「サンプル数」という言い方は誤用なので注意。)が大きければ「幅」は小さくなります。(同じ1%のコンバージョン率であっても、サンプルサイズ100の場合よりも、1000の方が幅は狭くなります。)
- サンプルに含まれる値のばらつきが小さければ幅は小さくなります。(サンプルの平均が、仮に同じく4%であっても、サンプルが1%、6%、10%、1%、2%であった場合と、4%、5%、4%、3%、4%では、後者の場合の方が幅が小さくなります。※母比率についてのエラーバーを描く際にはばらつきという概念はありません。)
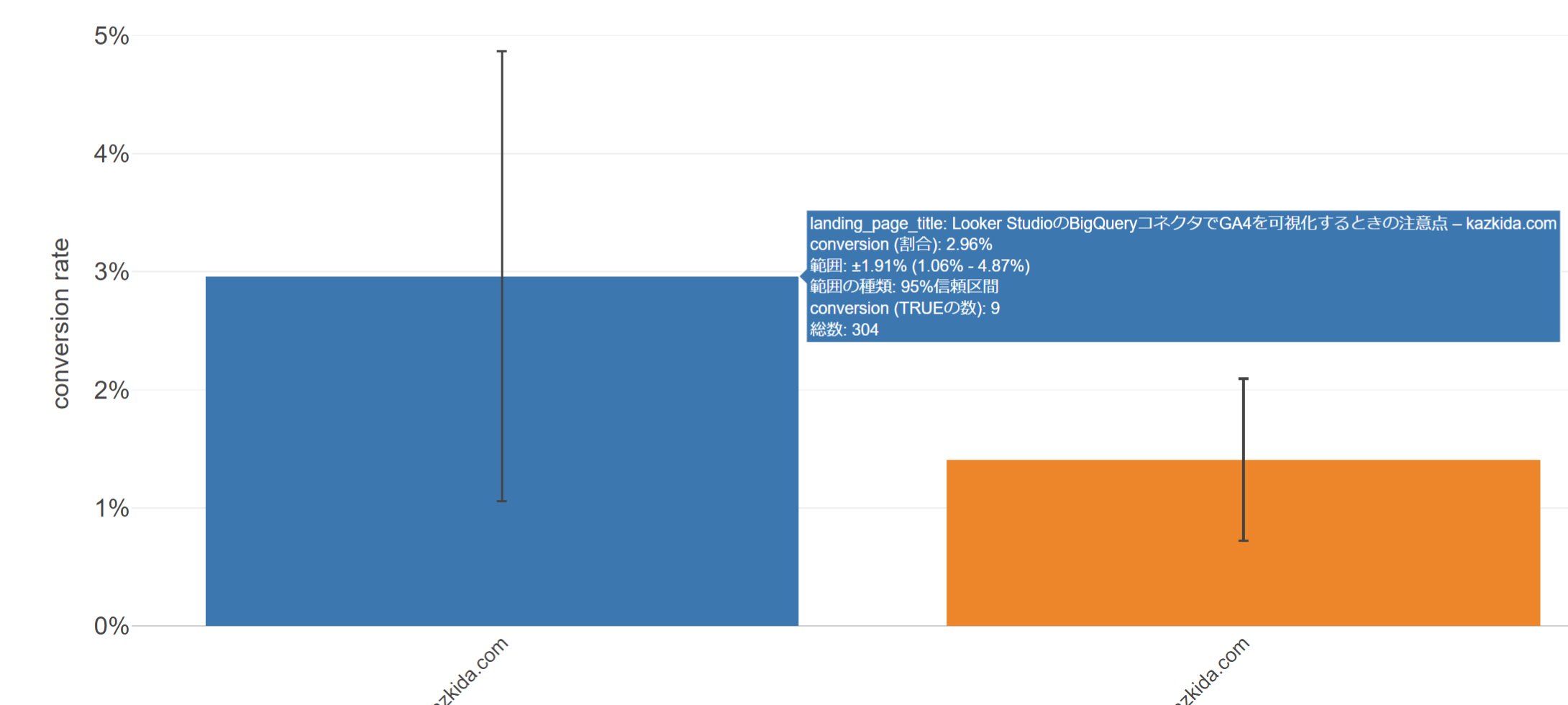
つまり、信頼区間は、サンプルサイズとばらつきの両方が加味されて描かれるという訳ですね。以下の図の吹き出しは左側の青いバーの95%信頼区間を示した詳細ですが、平均値である2.96%を中心に、上下1.91%の幅をもっていることがわかります。サンプルサイズ(この場合、セッション数)が304ということも確認できますね。
エラーバーの読み取り
エラーバーを描けたら、その読み取りです。
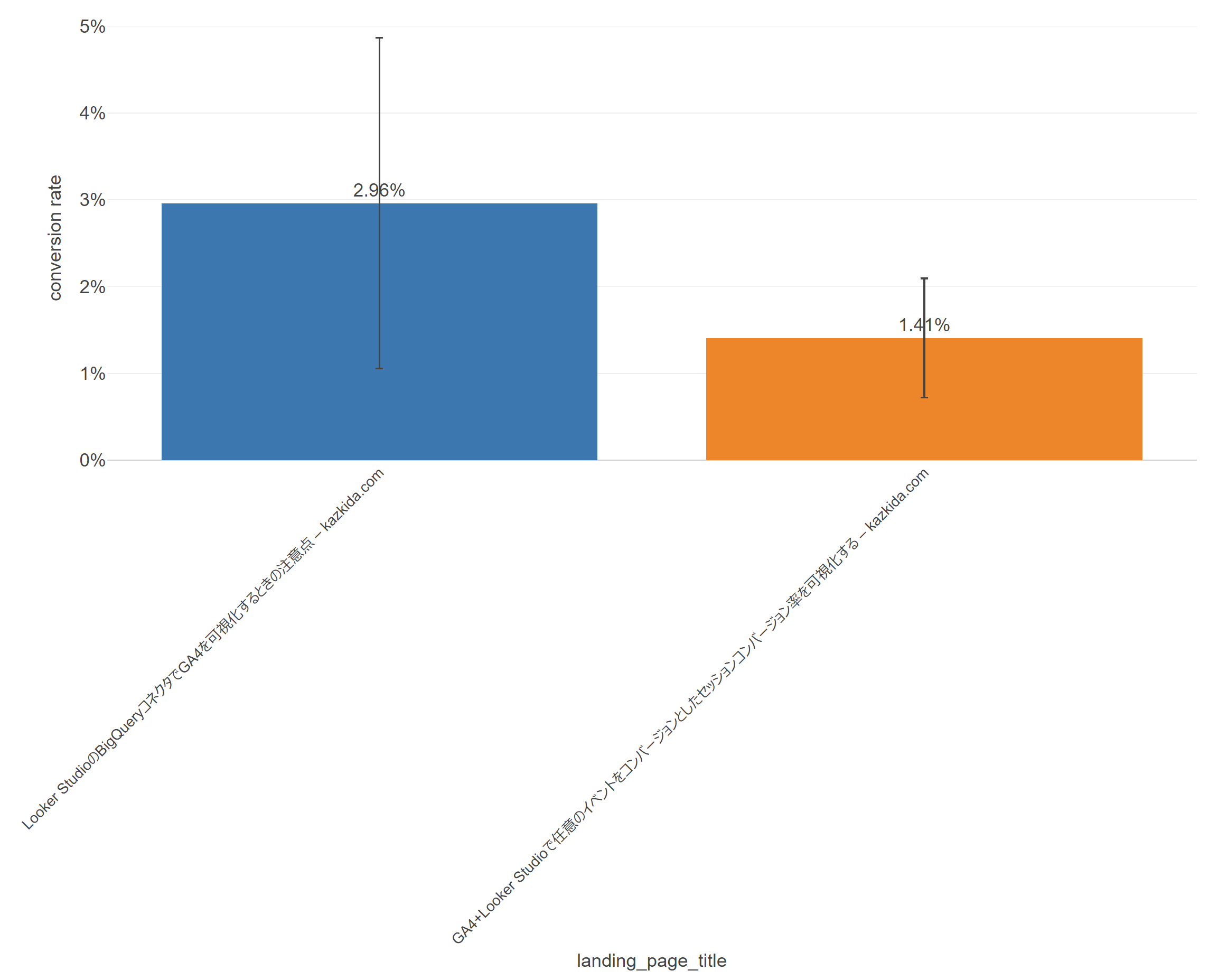
今、以下の、エラーバー付きバーチャートでは、2つのランディングページを比較し(つまり、ランディングページAにランディングするセッションという母集団と、ランディングページBにランディングするセッションという母集団を比較し)、その真値である母比率(全部のセッションのうち、いくつのセッションがコンバージョンするセッションであったのかの比率)を推定しています。
そして、2つのエラーバーが示す範囲は重なっています。重なっているということは取得したサンプル(=今、Google アナリティクスに記録されている値)では、2.96%と、1.41%という差があるけれど、それはたまたまであって、2つの母集団の真値は同じか、あるいは逆転する場合がある。と読み取ります。
そして、2つのランディングページ別のコンバージョン率には統計的に有意な差はない。と判断します。「点推定」(2.96%と1.41%のように母数を点で推定する方法)ではコンバージョン率は倍くらい違うので、絶対に差があると判断しそうですが、区間推定を行った結果は逆になるということですね。
まとめ
この記事では、以下をお伝えしました。
- Google アナリティクスが取得し、レポートとして表示している指標を「サンプル」だと捉える視点を持ったほうが良い。
- 仮にサンプルだとすれば、そのサンプルをもとに母数(=真値)を推定できる。
- 推定の方法としては、点推定(一つの値で推定する)と区間推定(幅をもった値で推定する)の2つがあるが、場合によっては、結論が逆転する。
- 特にサンプルサイズが小さかったり、サンプルにおける値のばらつきが大きい場合には、信頼区間の幅が広くなり、エラーバーが重なり、結果として統計的に有意な差ではない場合があるので、注意が必要。
- 推定区間をビジュアルに確認するチャートとして、エラーバー付きバーチャートがある。
次回の記事では、Exploratory Publicを利用して簡単にエラーバー付きバーチャートを描く方法を紹介します。「Tableauの次」のツールをお探しの方、お楽しみに。