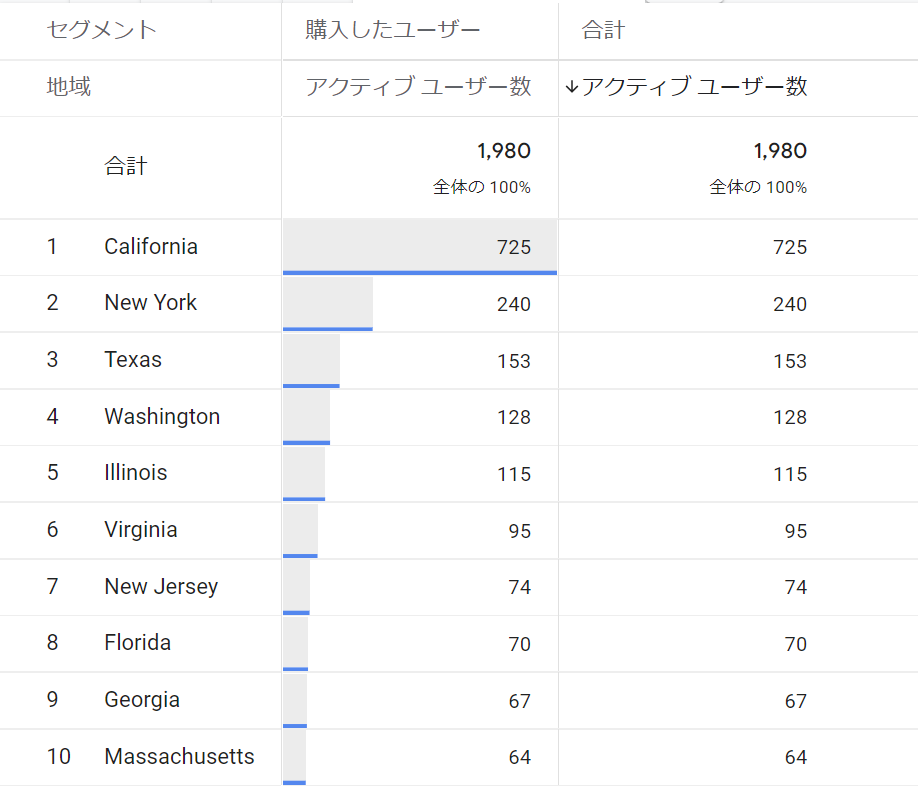
GA4のブラウザUIで、「コンバージョンしたユーザーはどの地域からが多いのだろう?」という質問に回答するのは、比較的簡単です。
自由形式の探索配下から自由形式レポートを開き、以下の設定をすれば良いです。
- ユーザーセグメント:コンバージョンしたユーザー
- ディメンション:地域
- 指標:アクティブユーザー数
一方、BigQuery上のGA4データに対し、SQLを書いて同じことを実現しようと思うと、少し戸惑うSQL初学者の人もいらっしゃるんじゃないかと思います。そこでこの記事では、BigQuery上のGA4データに対して「ユーザーセグメント」を適用し、同セグメントが適用された状態の分析をする方法を紹介したいと思います。
この記事で紹介するのは、比較的汎用性の高いテクニックだと思います。つまり、このブログで紹介する方法を理解すれば、ユーザーセグメントを、「コンバージョンしたユーザー」の代わりに「特定ページを見たユーザー」や「特定ページをスクロールしたユーザー」にすることも比較的容易ですし、ECサイトでは「商品●●を購入したユーザー」のようなユーザーセグメントを作成するといった応用もできます。
また、多少の応用で、セッションセグメントについても抽出できるでしょう。
BigQuery上のGA4データにユーザーセグメントを適用する流れ
BigQuery上のGA4データに「コンバージョンしたユーザー」を条件とするユーザーセグメントを適用するおおまかな流れは以下の通りです。
- with句で「コンバージョンしたユーザー」に限定した、user_pseudo_idのリストを作成する。user_pseudo_idとはBigQuery上でユーザーを識別する匿名のIDです。(デモサイトのデータを使うので、コンバージョンイベントは purchase としています)
- 本体のSQL文で、user_pseudo_idが、1で作成したuser_pseudo_idのリストに一致するという条件を付与する
流れ自体はかなりシンプルですね。
ユーザーセグメントをBigQuery上のGA4データに適用しているSQL文
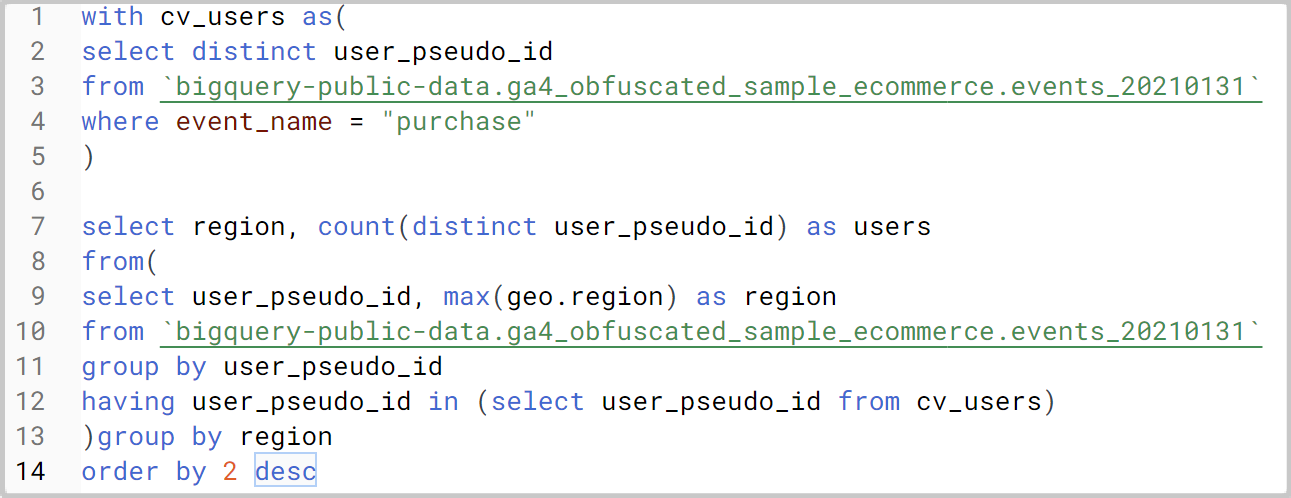
完成したSQL文(デモサイトのデータにアクセスできれば、動きます。)は以下の通りです。ページの下部にテキストでも載せておきますが、解説するには行番号があった方がやりやすいので、まずは画像で。
ポイントを解説します。
with句(1行目~5行目)のポイント
with句のポイントは以下の3点です。ちなみに、with句は仮想のテーブルを作る記述だと理解してください。
- select文で取得しているのは、ただ1列、user_pseud_idだけです。
- select文に distict オプションを付けているので、重複は除外しています。
- where句で purchaseイベントが発生した行に絞り込んでいます
これで、with句では「purchaseイベントを発生させた user_pseudo_idの重複のないリスト」が完成しています。
本体のSQL(7行目から14行目)のポイント
本体のSQLのポイントは以下の3点です。ちなみに、”内側”のサブクエリが9行目から12行目です。それ以外は外側ですが、外側は、単純にregionごとにuser_pseudo_idのユニークな個数を集計しているだけですので、ポイントは内側のサブクエリにあります。
- 9行目の集計関数 max(geo.region)と、11行目の group by 句で、一つのuser_pseudo_idに対して一つの regionが紐づくような仮想のテーブルを作っています。(※)
- 12行目の having句では、「集計された表」に対する絞り込みを行っています。集計されていない表に対しては where句が使えるのですが、集計された表にはhaving句を使わないとエラーになります。ここで言っている「集計された表」とは、「user_pseudo_idごとの、maxのregion」のことです。
- 12行目のinという比較演算子は、X in (“A”, “B”,”C”) のような書式で用いることが一般的です。その場合、「XがAかBかCに等しい」という条件を表します。一方、この12行目の使い方は、「user_pseudo_id が、(select user_pseudo_id from cv_users) を実行した結果、リストとして取得されるuser_pseudo_idのどれかと一致する」ということを意味します。この行こそが、ユーザーセグメントを適用している行だといえます。
| ※ この、枠の中の記述は初心者の方は読み飛ばして頂いて大丈夫です。 geo.regionは、GA4のレポートでは「地域」にあたります。「地域」は一般にユーザースコープと考えられています。GA4のUIでもユーザースコープと表記されている場所があるので、もしかすると、Google的にもユーザースコープという認識なのかもしれません。 一方、スマホやノートパソコンが広く利用されているので、1人のユーザーが(=一つのブラウザが)東京からも千葉からも同一のサイトに訪問することは十分にありえます。ということはユーザーに対して、地域は一意にはひも付きません。つまり、ユーザースコープではありません。 それを考えると、user_pseudo_idごとに max(geo.region)で地域を一意に紐づけてしまうのは実はとても乱暴です。(地域名のアルファベット順で一番最後に出てくる地域を無条件に取得してしまっているのです。)本記事の主目的ではないので、あえて、max(geo.region)としてしまっていますが、厳密性を問われる場合には、「コンバージョンが発生したセッションのgeo.region」とか、「コンバージョンしたユーザーが最も頻繁に利用したgeo.region」を取得する必要があります。 以下が、本サイトのGA4がエクスポートしたBigQueryでユーザーごとのgeo.regionを可視化してみたものですが、同一のユーザーが複数のgeo.regionからサイトを利用してくれるのは珍しいことではないな。と分かります。 https://i.gyazo.com/0db571270b977b58eff42efb5a320394.png |
SQL文はテキストでも載せておきます。(ユーザーセグメントを適用する方法は他にもありますが、この方法が私としては一番簡単だと思います。)
with cv_users as(
select distinct user_pseudo_id
from `bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131`
where event_name = "purchase"
)
select region, count(distinct user_pseudo_id) as users
from(
select user_pseudo_id, max(geo.region) as region
from `bigquery-public-data.ga4_obfuscated_sample_ecommerce.events_20210131`
group by user_pseudo_id
having user_pseudo_id in (select user_pseudo_id from cv_users)
)group by region
order by 2 desc宣伝
Udemyでは、BigQueryを勉強の基盤としてSQLを学ぶ動画講座を展開しています。11時間の動画と800枚以上のスライドで、手を動かしながらSQLを学べる講座ですので、この機会にSQLを勉強しようという方はぜひご利用ください。お陰様で評判もなかなか良いようです。
リンクすると講座にジャンプします。